


Paragraph segmentation in Trados and memoQ
Understanding the fundamentally different approaches

When texts to translate are imported into a working environment such as Trados Studio or memoQ, the platforms chosen as examples for the present discussion, the text is typically divided into parts to facilitate a better focus on important elements in the text content. This can help top avoid some common problems found in work done in word processing software, for example, where sentences or even entire paragraphs are sometimes overlooked, particularly where several passages on the same page may be very similar.
The manner in which the imported text is broken up into portions for translation work falls into two general categories. The most common method applied is sentence-based segmentation, which roughly corresponds to punctuated sentences in the text but may also follow other guidelines such as sub-sentence punctuation (colons and semicolons, for example) or even specially defined words or markers. This form of segmentation is a subject for another day. The second, less common form of segmentation, paragraph-based segmentation, divides the text into blocks defined by paragraph markers or other major structural elements, such as cells in a spreadsheet or tags defined as “external”. In my past work, I have tended to choose this segmentation option for translating source texts which are poorly written and require considerable restructuring to produce a logically consistent translation which reads well.
Typically, a translation environment tool has a set of defined rules for text segmentation, but, depending on the tool, there may be additional elements or layers affecting segmentation, such as abbreviation lists or special settings in an import filter for a particular file type. Keep that in mind if you encounter deviations from “the rules”.
The technical details involved to apply a segmentation strategy to a text differ with each working environment. In evaluating such features, I think it is most helpful to consider very carefully what opportunities for structuring workflows well may be gained or lost as a result of different approaches to segmentation.
It should also be noted that there is a segmentation resource exchange “standard” (SRX), but it is not implemented in all the major environments, and where I have seen it implemented, I often have to struggle with a sense of indignation at the inefficiency and incompetence, as well as the syntax variations in implementation of the alleged standard. ‘Nuff said about that for now.
Take a turn with Trados
Trados Studio currently has more licenses in use than any other translation environment. So of course those who own the platform (this has changed a number of times thanks to M&A roulette, reminding me at times of the “hot potato” game we played as children) feel little need to follow standards, including exchange standards for segmentation. So to reproduce segmentation behaviors of other tools in Trados or to mirror Trados segmentation elsewhere, it is necessary to know where to find equivalent functions affecting segmentation under several rubrics.
But first you must know that in Trados, segmentation and many other features are tied to translation memories (TMs); segmentation features do not exist as independent resources. Moreover, there is really no convenient way to back up segmentation-related features nor to transfer these to other exiting TMs (though new ones can be created with the features of an existing translation memory). To access segmentation-related information in Trados Studio, one must right-click the relevant TM and select Settings from the context menu:

In the Settings dialog, the relevant features will be found under Language Resources:
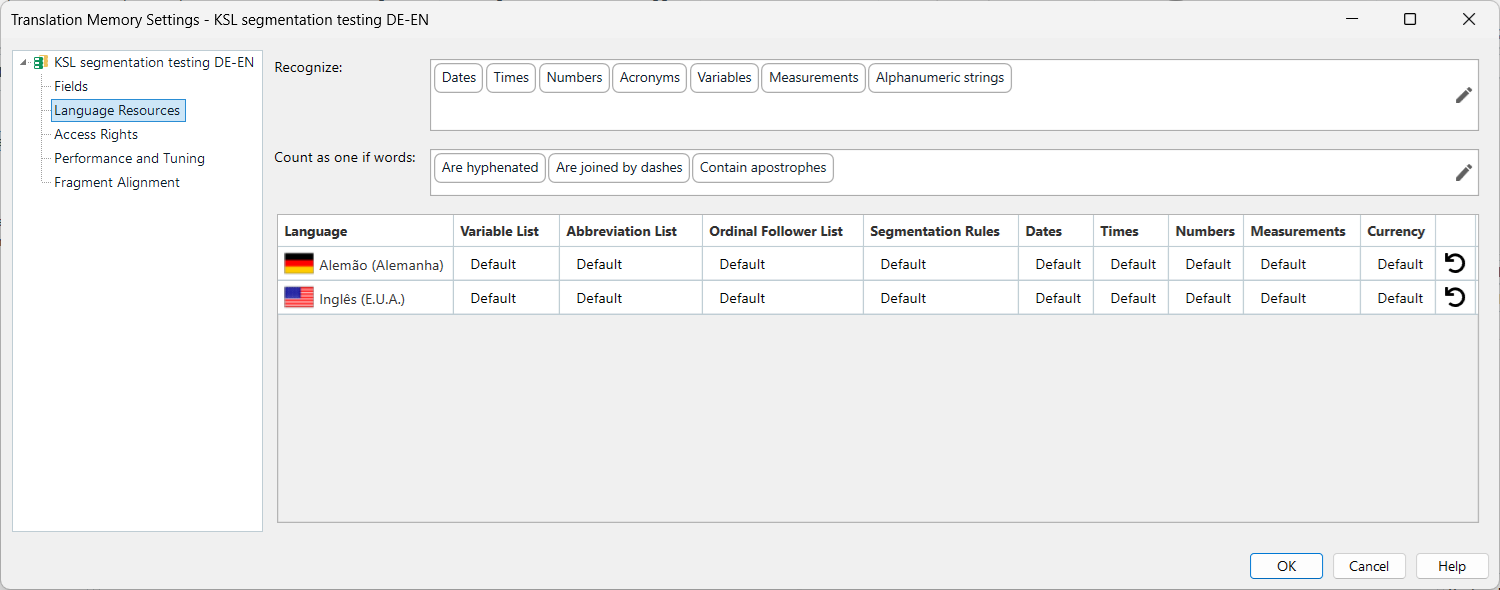
In a discussion of sentence-based segmentation, I would point out that, in addition to the Segmentation Rules for both languages, the Abbreviations List and Ordinal Follower List are also important, but that isn’t the case for paragraph-based segmentation. For that we need only examine the segmentation rules. Clicking in the row for either language in that column will open the rules dialog for that language in the TM:

The default rules are inevitably for sentence-based segmentation, but to switch to paragraph segmentation, simply select the radio button for that and then OK.

All the buttons and other elements related to rules are greyed out; no further configuration is needed. However, when the OK button is clicked, a warning is displayed:

OMG, really? If you had custom rules configured for the sentence-based segmentation, they will all be lost now. And there is no convenient way to back them up as a set, so if the change back to sentence segmentation is made later, all those rules will have to be re-entered manually. In other words, Trados Studio is not a tool that allows carefree switching of configured segmentation rules. But that isn’t a problem for the average Trados user, because segmentation rule changes are such an utter, confusing pain in the tush that few ever learn much about the topic, much less master it.
And memoQ?
Segmentation in the world’s second most popular translation platform, memoQ, is not tied to translation memories. Any number of segmentation rulesets can be created for any language, and these resources may be switched quickly and easily for particular files in a project. Different segmentation rules can be used with different projects that share a working translation memory. Segmentation rulesets can also be exported to resource files, which can be implemented by importing them in other memoQ installations, and rules may be uploaded to a memoQ TMS server from any desktop client with the necessary access privileges. So overall it is simpler to develop, manage and share segmentation resources compared to Trados Studio. Moreover, all the segmentation-relevant rules mentioned as different Language Resources categories in Trados are united in memoQ segmentation rules and are thus easier to keep track of. Oh, and the SRX standard is also a thing in memoQ, so segmentation rules can be imported or exported using that standard (some SRX version adjustments may be needed), enabling better process compatibility for interoperability with some other tools.
But implementing paragraph-based segmentation in memoQ is less obvious than in Trados Studio. Not because it’s particularly hard, but rather because as of the current version of memoQ (10.6) there is no “paragraph segmentation” button, nor is there any documentation from memoQ Ltd. as to how to accomplish that sort of segmentation. But it’s easy to create paragraph segmentation resources, which can be selected and used as needed for a given language.
There are two ways to create a paragraph segmentation ruleset in memoQ. One of these I documented long ago, in the days before memoQ switched to a ribbon interface, and as this video shows, you simply create a new ruleset and then delete all the rules in it:
Another less obnoxious method involves modifying the content of the #end# group in the rules. That is the list of characters which define the end of a sentence typically. In the simplified interface for current segmentation rules, the list appears at the top of the dialog (marked in red here):

In the Advanced view or in older segmentation rules (prior to version 7.8) or some which have been modified unskillfully, the #end# list will be found on the Custom Lists tab:

To get paragraph segmentation, simply delete all the items in that list and then add one item (text string) which will never occur. The list cannot be empty; if it is, there may be some rather strange segmentation malfunctions. So…
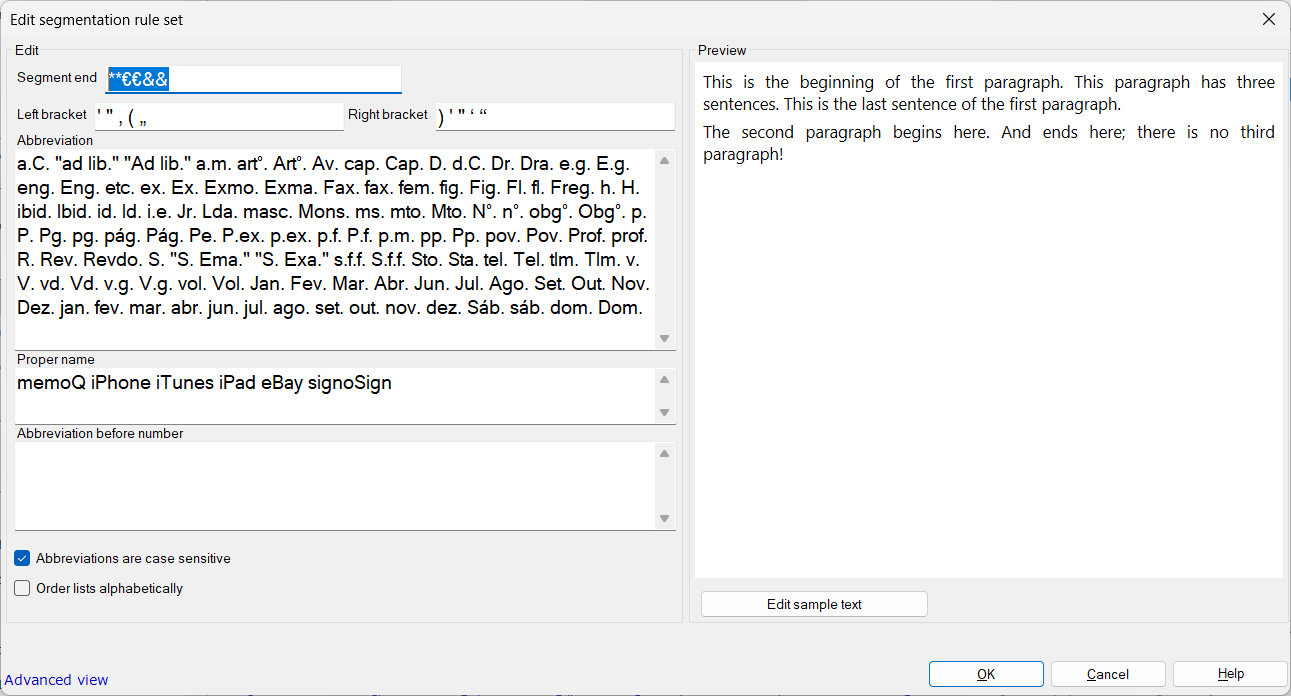
… in the screenshot example above, I have just one item in that Segment end list, a nonsense string of six characters (**€€&&), and as you can see in the preview on the right, the text now segments by paragraph.
Please note: this change of the #end# punctuation list must be made in the Advanced view, not in the field of the Simple view!

If you try to paste the nonsense string (or any words) into that field of the Simple view, the editor bill break up the string and make a separate entry in the #end# list for each character.
Please note that with certain filters, such as those for Microsoft Word files, line breaks or other elements may cause segmentation beyond what is defined in the segmentation rules (as shown also in the video above), so adjustments to import filter settings may also be needed in some cases.

Thanks for the Trados memoQ comparison of paragraph segmentation, Kevin. Interesting that you used this segmentation in the past for poorly written texts that need significant restructuring but don't appear to do so now. Why's that? I found big chunks harder to process visually, which is why I don't use it, but agree that it solves major restructuring that can't be achieved through quick segment merges across two or three sentences.
By the way, I recommend the "applyTM Template" app in Trados. With a language resource template, you can then apply any or all of your custom rules to any or all of your TMs, achieving precisely the convenient and "carefree switching" that you said you missed in Trados. 😉
Great article!
I appreciate your response to my comment on YouTube the other day and introducing your blog.
I'm curious how you managed to use a "string" in the Segment End area on MemoQ.
In the past I've tried to use a string of characters (went back and tried it again just now with the one in your example) and when I close the dialogue and reopen it, it seems that memoQ automatically separates each character so they are individualized. In addition, repeated characters in that string are removed, so in the example you had I it shows up as this: * € &
This would end up giving me a new segment every time any of these characters is used individually, which is definitely not what I want!