


Deep inside... translation packages! And more.
ZIP it good!

Spoiler: almost everything turns out to be a ZIP file with the extension changed.

We’ve all seen them in one form or another.
Project packages from CAT tools like Trados Studio (SDLPPX or the SDLRPX return packages, memoQ (MQOUT or the MQBACK return packages), STAR Transit (PXF or PPF, or the TXF and TPF return packages, Wordfast (GLP) et alia.
Project backup files or TMS server backups.
Microsoft Office files from Office 2007 onward (DOCX, XSLX, PPTX).
All of these file types are really just *.zip files of a particular internal structure, with the extensions renamed. And the same is true for a whole lot of other files we might deal with routinely. The ZIP archive format is extraordinarily popular with software developers as a means of bundling many different elements into a collection of information for various purposes. But why is that relevant to translators, project managers, localization engineers and others chipping away at the wordface?
There is no single answer, of course. The answers are more numerous than the many extensions which hide the underlying structure of the files in question.

Let’s take a Microsoft Word DOCX file as an example. This “word processing file” probably contains some text. That text might have various kinds of formatting: diverse typefaces in various sizes, perhaps even different colors or others formats for emphasis, highlights, etc. There might be pictures included with the text. There might even be other file types such as spreadsheets or presentation slides included for reference and illustration.
In translation work, it is often difficult to handle elements other than the text and its formatting. This depends, of course on whether one uses specialized translation environment tools and which ones, but embedded graphics, diagrams or chart objects, slides and spreadsheets often have text content (or text image content) which cannot be read by a given tool. In-situ editing is often possible in Microsoft Word, but not always, and if there are many such embeddings, the process of translating these additional “texts” can be obnoxious, to put it mildly.
Back in 2012, I published the first of a series of articles describing how to extract content from DOCX or other Microsoft Office formats. When a DOCX file is unzipped, the top level structure of the resultant folder looks like this:
The word subfolder is where the content of interest is stored. That content may appear in a number of places.
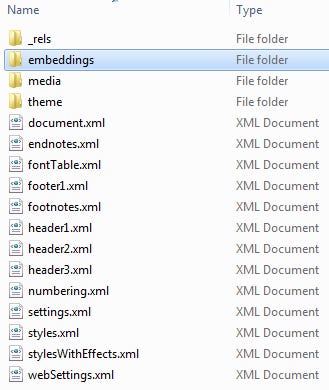
Much of the time, the content one needs to access and translate (perhaps by separate import to a CAT tool if not handled by the compound document filters) will be in the embeddings folder. DOCX files which were produced by converting older DOC formats or RTF files, for example, might have embedded content included as mysterious BIN files; I have described how to deal with these in another old blog post. I also published videos showing how to extract embedded context and replace it in the DOCX structure after translation or modification.
Some content, like bitmapped graphics, may be found in the media folder. The document.xml file contains the main text and might be useful for isolating and translating specific formatted text (which will always be marked by tags). One example of doing this in memoQ using the Regex Text Filter, can be found here. Another example for special filtering of DOCX and PPTX (PowerPoint) content in the document.xml file is here, with a video to show how it all works. These procedures can be configured for any worthwhile modern CAT tool, not just memoQ.
With the examples given here, translators, project managers and technical support staff should be able to figure out how to access content their CAT tool filters cannot deal with. Sometimes content includes text in hopelessly fractured configurations (like each letter of each word being in its own field), but even then there are useful ways of localizing the content without too much stress using external graphics or editing tools such as iceni InFix.

Translation packages, such as Trados Studio’s *.sdlppx files or the *.sdlrpx return packages are other frequently encountered ZIP files in translation and localization work. If one’s working tools cannot import these formats or have problems with a particular package, it’s possible to dissect them after unpacking and then deal with the desired parts of the packaged project more easily. Another of my articles from 2012 showed details of how to open SDLPPX packages and take the parts needed for translation. The target language folder will contain the segmented SDLXLIFF files for translation; the source language folder will have other SDLXLIFFs (unsegmented, don’t use these!) and the original format source files for the translation. In other words, it is not necessary to ask the client for the original files if you receive a package, as these are already included. If the SDLXLIFF files are corrupted, these original files can be translated if one is unable to obtain uncorrupted bilingual files. The packages may also contain translation memory or terminology resources in formats for which a number of easy access options are available.
Trados Studio return packages (SDLRPX) are a source of unnecessary worry by too many people. I’ve lost track of how many times people have asked on social media or CAT tool discussion mail lists whether their proprietary translation memories, term bases or other resources are included in the return package sent to the client. Never mind that the answer can be found in many places. Let’s just use our ZIP tools to peek inside the package:
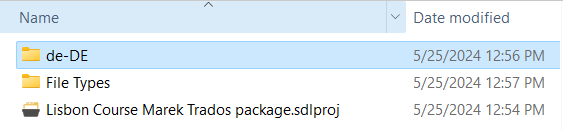
The screenshot above is from a return package in a project created for a course that Marek Pawelec and I taught in Lisbon in January 2024. The original project package (SDLPPX) contained translation memory and term base resources, and once imported into my working environment several more translation memories and term bases were attached for reference. The *.sdlproj file contains project information to allow the finished translation to be incorporated into the master project from which the translator package was generated. The File Types folder is simply a bunch of information files related to file formats and contains no translation data. The folder “de-DE” is for the target language (German from Germany) and contains the following:

Just the translated XLIFF files from the translator. (SDLXLIFF is a proprietary variant of the XLIFF standard.) Nothing else. No translation resource data other than the translated bilingual files are ever included in the return package. Nada. So no worries. The same is true for other return packages, such as those from STAR Transit projects.
Other translation environment packages can be taken apart in similar ways to access the content for translation. Examples of Wordfast GLP packages to translate in memoQ is shown in this article and this video. But whatever tools you prefer or may be obliged to use, understanding that all these packages can be inspected and their content extracted using common, often free and/or Open Source archiving tools such as 7zip or WinZip is the key to getting the job done or recovering the resources you need in a project emergency.
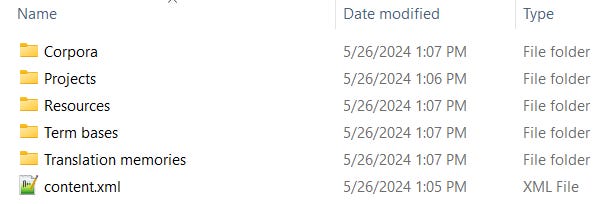
*.mqbk) fileSimilarly, backup files also typically use the ZIP format with the extension re-named. The screenshot above shows the content organization of the most recent memoQ backup format. If one wishes to restore project resources on an older version that may have difficulty with recent backups or to bypass the backup/restore wizard and just copy and install or register an individual resource, unzip the archive (rename the backup’s extension to *.zip if your archive tool is confused by the custom extension) and deal with the resources individually. For this example, it should be noted that the backed-up resources are in memoQ-specific formats, so in most cases they won’t be directly usable by those with other CAT tools, but any licensed or fully functional trial version of memoQ (free on a “virgin” computer which has not had memoQ installed previously) can be used to convert resources to exportable formats which can be used in other environments.